 Databázový systém má nepochybne jednu dôležitú úlohu a to je ukladanie údajov. Spôsob, ako presne sú údaje uložené, je transparentný a pri normálnom používaní ho ani nie je nutné poznať. Zaujímavé to začína byť až keď sa objaví nejaký problém. Vtedy je každá informácia dobrá a aj preto sa teraz v krátkom rýchlokurze pozrieme na to, ako údaje ukladá MS SQL Server.
Databázový systém má nepochybne jednu dôležitú úlohu a to je ukladanie údajov. Spôsob, ako presne sú údaje uložené, je transparentný a pri normálnom používaní ho ani nie je nutné poznať. Zaujímavé to začína byť až keď sa objaví nejaký problém. Vtedy je každá informácia dobrá a aj preto sa teraz v krátkom rýchlokurze pozrieme na to, ako údaje ukladá MS SQL Server.
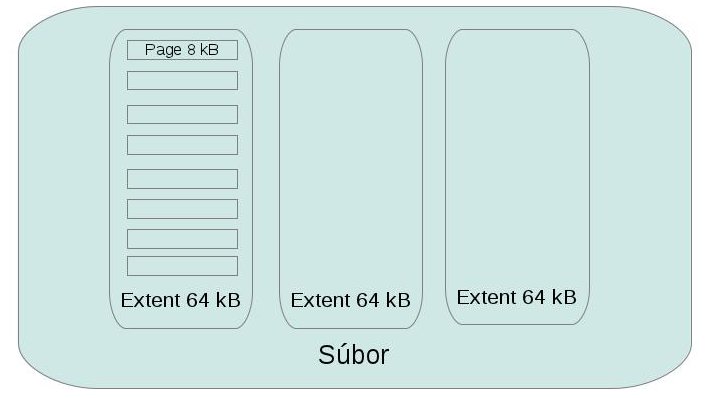
Základným princípom pre MS SQL Server je, že údaje ukladá v súboroch. Pre jednu databázu ich môže byť jeden alebo viac. V rámci servera ešte existuje niečo ako filegroupy. Je to logický kontajner, do ktorého môže patriť viacero súborov jednej databázy (filegroupa je teda podmnožina súborov databázy). Niečo ako adresár pre súbory, ale taký, ktorý vidí len server. Ak sa teda pozrieme do databázového súboru (okrem neho existuje ešte žurnálový súbor – ale o tom niekedy inokedy), tak môžeme vidieť, že súbor je rozdelený na tzv. extenty. Extent má 64Kb a predstavuje jednotku, ktorú server číta zo súboru. MS SQL Server je celkovo postavený na práci s blokmi údajov, pretože na posielanie po sieti napríklad používa Tabular Data Stream, ktorému tieto bloky tiež vyhovujú.Ak sa teda pozrieme to extentu, zistíme, že je tvorený ôsmimi stránkami (Page). Zatiaľ čo jeden extent môže obsahovať údaje pre rôzne tabuľky, stránka má už len údaje jednej tabuľky. Stránka je potom ďalej tvorená riadkami. Nie sú to tak celkom riadky, ktoré sa nachádzajú v tabuľke, lebo takýto jeden riadok môže mať veľkosť maximálne 8 060 B, zatiaľ čo riadok v tabuľke môže byť omnoho väčší. Preto sa môže stať, že na jeden riadok v tabuľke bude pripadať viac riadkov v súbore. Riadok má tiež svoju vnútornú štruktúru, ale pre účely tohto článku ju budeme brať ako najmenšiu jednotku.
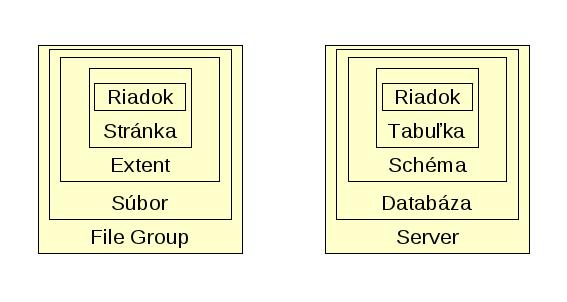
Je zaujímavé porovnať toto usporiadanie s logickým usporiadaním údajov z pohľadu relačnej databázy. Najzákladnejšou jednotkou je riadok, ale tam podobnosť končí, pretože zatiaľ čo pre ukladanie do súboru sú lepšie bloky údajov, z relačného pohľadu sa vyžadujú riadky v tabuľkách.
Toto ale nie sú všetky informácie, ktoré je o ukladaní údajov MS SQL Servera dobré vedieť. Súborové riadky totiž môžu byť nejako usporiadané, podľa toho aké vlastnosti pre danú tabuľku potrebujem. V podstate mám 3 možnosti:
1. Heap = hromada
2. Cluster Index = usporiadané
3. Table Partitions = usporiadané a rozdelené
Ak vytvorím tabuľku a nechám jej východzie nastavenia, tak to, čo dostanem v súbore, bude hromada. Riadky nie sú nijako usporiadané, vkladanie alebo mazanie je veľmi rýchle. S vyhľadávaním je to už o čosi horšie. Akonáhle potrebujem rýchlo vyhľadávať, tak mi každý lepší nástroj pre optimalizáciu poradí zapnúť Cluster Index. Cluster Index sa tak volá preto, pretože podľa zvoleného stĺpca vytvorí zhluky rovnakých hodnôt a potom ich usporiadané uloží do súboru. Takže mám veľmi rýchle vyhľadávanie, ale samozrejme vkladanie a mazanie si bude pýtať svoje. Posledná možnosť je Table Partitions. V takomto prípade sa údaje usporiadajú podľa jedného stĺpca a následne sa podľa tohto stĺpca a podmienky rozdelia do samostatných súborov. Výhoda toho celého je, že pri vyhľadávaní podľa stĺpca už dôjde len k načítaniu časti tabuľky, ktorá podľa podmienky zodpovedá vyhľadávanému výrazu. Table Partitions je dostupné až vo verzii Enterprise. Podobne ako údaje sú ukladané aj neclustrovené indexy (to sú ďalšie indexy, ktoré je možné nad tabuľkou zapnúť). Tie sú už ale tvorené len odkazmi do pôvodnej tabuľky, nie ako clustrovaný index, samotnými údajmi.
Zatiaľ čo uloženie údajov v súbore sa nedá nijako konfigurovať a ovplyvniť a jeho znalosť je užitočná hlavne pri riešení nízko úrovňových problémov, usporiadanie riadkov, prípadne ich rozdelenie do viacerých súborov je dôležitá konfigurácia, ktorá má vplyv na výkon servera. V takomto prípade je dôležité zvážiť, aké údaje budú v tabuľke ukladané a ktoré operácie majú byť tie rýchlejšie.